

Databricks for Modern Data Engineering: When to Use It & What It Can Do for Your Business
December 30, 2025

How many tools are required to keep your data pipelines running today?
The answer would be too many, right?
There would be one for ingestion, one for transformation, a separate tool for streaming, and another platform for preparing data for machine learning. This fragmented approach works fine until there is limited data flow. As soon as the business, sales, and customer base grow, data is automatically set to grow; that is where the system jeopardizes itself. It becomes difficult to manage, and challenges start to crop up.
If you, as a data engineer, analytics lead, or CTO, experience this challenge, it is time to shift your focus to Databricks for data engineering. Around 19% of organizations have invested in a data warehouse or analytics software and have adopted Databricks. It caters to more than 15,000 customers across the globe across various industries.
This platform eliminates the dependency on multiple tools required to process data, manage real-time updates, and run analytics. As a result, the task is accomplished faster with prompt insight availability and rapid data setup.
But is it always the right choice?
And how do you know when Databricks offers real value and when it creates unnecessary complexity?
This guide answers questions and offers insights on Databricks usage. It also explains the possibilities in modern data engineering and the measurable business impact it offers.
What is Databricks? A Quick Overview
It is an analytics platform that helps organizations evaluate, transform, and process heavy-volume data. It even brings multiple capabilities so that teams can collaborate and work on data. It starts right from ingestion to analytics without switching platforms.
Databricks supports:
- Data engineering
- Data science and machine learning
- SQL analytics and business intelligence
- Collaboration across technical teams
Databricks runs on cloud providers that allow automatic scalability of compute resources depending on workloads. It results in your team processing data rapidly at minimal costs.
Databricks and the Lakehouse Architecture
Data Lakehouse combines the best features of Data Lakes and Data warehouses.
Though traditional data lakes are quite cost-effective and flexible, they still fall short when it comes to meeting current customer expectations. On the other hand, data warehouses offer robust performance but come with a hefty cost and rigid structure. To overcome the challenges of both, Lakehouse merges them and offers a single architecture at a budget-friendly cost.
How Databricks Combines Data Lakes and Data Warehouses?
Databricks is a powerful analytics platform that allows companies to collect all types and forms of data under a single unified system. Though it makes storing under an economical cloud solution, Databricks makes speedy processing of the data just the way a traditional data warehouse works.
Here are the benefits of this collaborative approach:
- Easily store voluminous data.
- Accommodates multiple data types
- Minimal storage costing
- High-performance analytics
- Built-in governance and access control
Databricks accommodates modern data engineering requirements, and as an organization, you will be able to manage larger and complex data easily.
Why is Databricks Popular for Modern Data Engineering?
Modern data engineering works well with platforms that manage scalability, agility, and complexity while controlling operational overheads. Besides, with growing data ecosystems, internal teams would struggle to keep the pipelines ready for the future. To overcome this challenge, Databricks emerges as a prominent data engineering platform to function for modern data teams.
Here are the core reasons why Databricks is a Go-To platform for Data engineers:
Created for Big Data Scale and Complexity
Databricks can process even high-volume datasets across distributed systems, which makes it well-suited for enterprise-scale workloads.
Supports Both Batch and Streaming Data
Data engineers help develop pipelines for historical data and real-time data streams within the same platform, which results in less dependence on tools.
Cloud-native and Elastic
Another benefit that you can avail from Databricks is its automatic scalability of computing resources up or down, depending on workload requirements, and improving performance while optimizing costs.
While these were the benefits, there are also challenges that Databricks addresses.
Key Data Engineering Challenges Databricks Solves
Engineering teams face challenges that make the delivery sluggish and increase complexity. However, with the introduction of Databricks, you can expect a sure-shot solution to every challenge mentioned below:
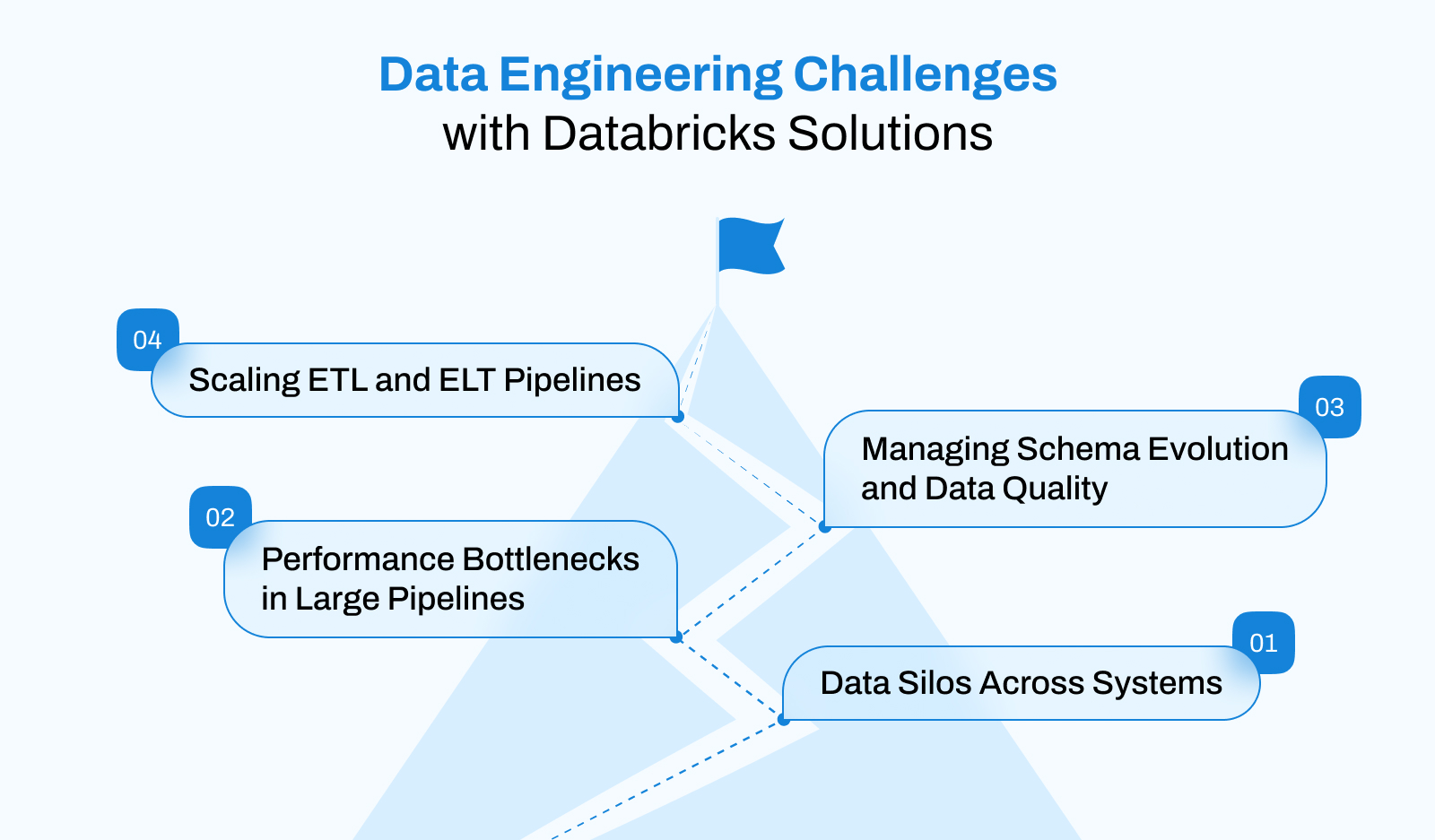
Data Silos Across Systems
Since there are multiple departments at your organization, data would be widely spread across multiple tools and platforms. As a result, there will be integration difficulties and visibility limitations.
Performance Bottlenecks in Large Pipelines
If there is no upgradation in traditional ETL processes, then that would be another challenge of handling high data volumes and complex transformations.
Managing Schema Evolution and Data Quality
When you change data structures, there are chances of pipeline breakage that can lead to inconsistent analytics.
Scaling ETL and ELT Pipelines
As data grows, pipelines must scale reliably without constant rework.
Databrick is the ultimate solution for all the challenges that we discussed above. It centralized data processing, enforcing reliability through Delta Lake, and offers scalable compute for demanding workloads.
Databricks’ Role in the Modern Data Stack
Databricks fits seamlessly into a modern data stack. Besides, it is considered a central processing and analytics layer rather than a standalone system.
You can integrate with:
Cloud storage platforms like:
- AWS S3
- Azure Data Lake Storage
- Google Cloud Storage
Downstream and Complementary tools like
- BI and Visualization tools
- Data orchestration and workflow tools
- Machine Learning and AI platforms
With this, the organization can easily adopt Databricks, lay a solid foundation for modern data engineering, while keeping the ecosystem operational.
Undoubtedly, Databricks is a good fit for modern data architectures, but the true value comes from the features data engineers depend on. It helps with scalable processing, reliable pipelines, and support for both batch and real-time platforms.
Key Databricks Features for Data Engineering Teams
Databricks consists of ample features that allow data engineers to use and build scalable data pipelines. Such features are designed to manage large, heavy-volume data, maintain reliability, and support both real-time and batch processing.
Apache Spark at Scale
This one rests at the core of Databricks, which ensures distributed data processing. Databricks offers a fully managed and reliable environment that enables simplicity when it comes to handling cluster management.
Here are the benefits to expect:
- Easy handling of the database across multiple nodes
- Optimizes performance using smart query execution and caching
- Multi-language support
Delta Lake for Reliable Data Pipelines
For analytics and downstream apps, reliable data pipelines are extremely important. To keep the consistency, governance, and reliability intact, Databricks uses Delta Lakes.
Here is how it benefits your business:
- ACID transactions for consistent and reliable data updates
- Protecting data quality constantly, irrespective of structural changes, using Schema enforcement and Schema evolution
- Time travel and data versioning to monitor changes or recover data from pipeline leakages
Databricks Workflows and Job Orchestration
There is no third-party dependency, as Databricks consists of several built-in tools that automate and manage data engineering workflows.
Here are their capabilities:
- Implementing data pipelines with explained execution intervals
- Handling task dependencies
- Production-ready automation for batch and streaming workloads
Streaming and Real-Time Data Processing
Data engineering requires data for processing. Databricks allows real-time analytics using structured streaming, which allows fault-tolerant streaming.
Here are common streaming use cases:
- IOT and sensor data processing
- Clickstream and user behavior analytics
- Event-driven data pipelines
Built-in Collaboration and Notebooks
Databricks allows cross-functional teams to collaborate and work together.
Here is how it works:
- Shared notebooks for development and experimentation
- Version control integration for better code generation
- Seamless collaboration between data engineers and data scientists within a single environment
There is no doubt about the excellent features of Databricks, making the development and management of data pipelines easier. But such capabilities offer immense value when applied to the right use cases.
Getting Started with Databricks for Data Engineering
Databricks is an architectural and operational shift, along with a technological decision. Enterprises with a structured approach align their platform with data strategy, business objectives, and internal team strengths, and achieve sure-shot success. As a leading software development and data engineering services provider, we have noticed that preplanning leads to a difference in the long-term value.
Initiate with the Right Foundation
You must decide where Databricks fits best in your existing environment. It includes:
- Selecting the cloud provider based on your existing infrastructure
- Determining a Lakehouse architecture to support both current and future use cases
- Sorting out the key data sources, workloads, and performance requirements
You are halfway through with a strategy and a detailed blueprint. It will remove rework and allow Databricks integration to occur swiftly with your data ecosystem.
Prepare Your Data Engineering Workflows
It is important to evaluate the following things before starting migration or the development of new pipelines.
- Existing ETL or ELT processes
- Data quality and governance requirements
- Batch vs streaming workload priorities
Large enterprises start with use cases. For example, undertaking modernization of a data lake or preparing the pipeline performance better to gain value quickly before scaling.
Build for Scalability and Reliability
Databricks implementation includes best practices:
- Designing pipelines with Delta Lake for dependency and data quality
- Executing cost and performance tracking
- Implementing security, access controls, and compliance standards
It assures you that your data engineering workflows are ready to be used from the start.
Enable Your Team for Long-Term Success
Lastly, the success of Databricks depends on the right people and their willingness to cope with.
- Platform onboarding and skill development
- Defining development and deployment standards
- Collaborating across data engineering, ML teams, and analytics
Not Sure If Databricks Fits Your Data Engineering Needs?
Our data experts help you assess workloads, architecture, and cost efficiency to determine when Databricks is the right choice, and how to implement it the right way.
Conclusion
Modern data engineering platforms have a single expectation, and that is only fulfilled with a platform that scales automatically. It even supports real-time advanced analytics and remains reliable. Databricks can unify data processing, storage, and analytics into a cloud-based platform developed for modern data architectures.
However, Databricks, when aligned with the suitable use cases, offers maximum value to its users. Several use cases, like heavy volume data, complex transformations, and analytics strategies, extend beyond basic reporting. Databricks enable future-ready data pipelines to support AI-driven initiatives and business insights.
In the end, you must decide to adopt Databricks based on your data maturity, long-term goals, and team readiness. With a suitable strategy and implementation approach, Databricks helps move data engineering from a bottleneck to a competitive benefit.
SPEC INDIA is your trusted partner for AI-driven software solutions, with proven expertise in digital transformation and innovative technology services. We deliver secure, reliable, and high-quality IT solutions to clients worldwide. As an ISO/IEC 27001:2022 certified company, we follow the highest standards for data security and quality. Our team applies proven project management methods, flexible engagement models, and modern infrastructure to deliver outstanding results. With skilled professionals and years of experience, we turn ideas into impactful solutions that drive business growth.
Table of contents
- What is Databricks? A Quick Overview
- How Databricks Combines Data Lakes and Data Warehouses?
- Why is Databricks Popular for Modern Data Engineering?
- Key Data Engineering Challenges Databricks Solves
- Databricks’ Role in the Modern Data Stack
- Key Databricks Features for Data Engineering Teams
- Getting Started with Databricks for Data Engineering
- Conclusion
Delivering Digital Outcomes To Accelerate Growth
Let’s TalkTable of contents
- What is Databricks? A Quick Overview
- How Databricks Combines Data Lakes and Data Warehouses?
- Why is Databricks Popular for Modern Data Engineering?
- Key Data Engineering Challenges Databricks Solves
- Databricks’ Role in the Modern Data Stack
- Key Databricks Features for Data Engineering Teams
- Getting Started with Databricks for Data Engineering
- Conclusion
Delivering Digital Outcomes To Accelerate Growth
Let’s TalkRelated Blogs




Let’s get in touch!
India
SPEC House, Parth Complex, Near Swastik Cross Roads, Navarangpura, Ahmedabad 380009, INDIA.
-
 +91-79-26404031, 32-33-34
+91-79-26404031, 32-33-34 -
 [email protected]
[email protected]
