

Best Practices for Building a Scalable Data Warehouse
January 19, 2026

The volume of data is increasing at a rate that most companies do not fully expect. Organizations today produce more data than ever before, with over 2.5 quintillion bytes daily on not only customer transactions and mobile applications, but also Internet of Things (IoT) devices and third-party solutions. The actual problem is not gathering this data, but rather, it is storing, controlling, and analysing it effectively as the business expands.
This is where a scalable data warehouse is necessary. A warehouse designed to meet the needs of today may initially perform well, but as the amount of data, users, and reporting demands increase, cracks start to emerge. Inquiries become slow, infrastructure expenses rise, and departments begin to lose confidence in the information that they use to make decisions.
Industry statistics show that more than 60% of data projects end in failure because of inappropriate planning and architecture decisions during the early stages. That is why scalability is not somethin
Currently, scalable systems favor ELT (Extract, Load, Transform) instead of traditional ETL:
g you should add later, but rather some of the features that you need to integrate into your data warehouse.
In this blog, we are going to discuss some data warehouse best practices that can help you store your data in an effective way. These practices will assist in ensuring that your data platform scales well as your business, rather than becoming a bottleneck, due to the selection of the appropriate architecture and use of cloud platforms.
Key Components of a Scalable Data Warehouse Architecture
To learn how a scalable data warehouse can scale smoothly, it is beneficial to learn the primary elements that operate in the background. Consider a data warehouse as a highly structured system where data is gathered, stored, processed, and handed over to be analyzed. Every element performs a certain task, and when one of the elements is not strong, then the scalability and performance could be affected.
Here are the key components of data warehouse architecture explained in a simple way:
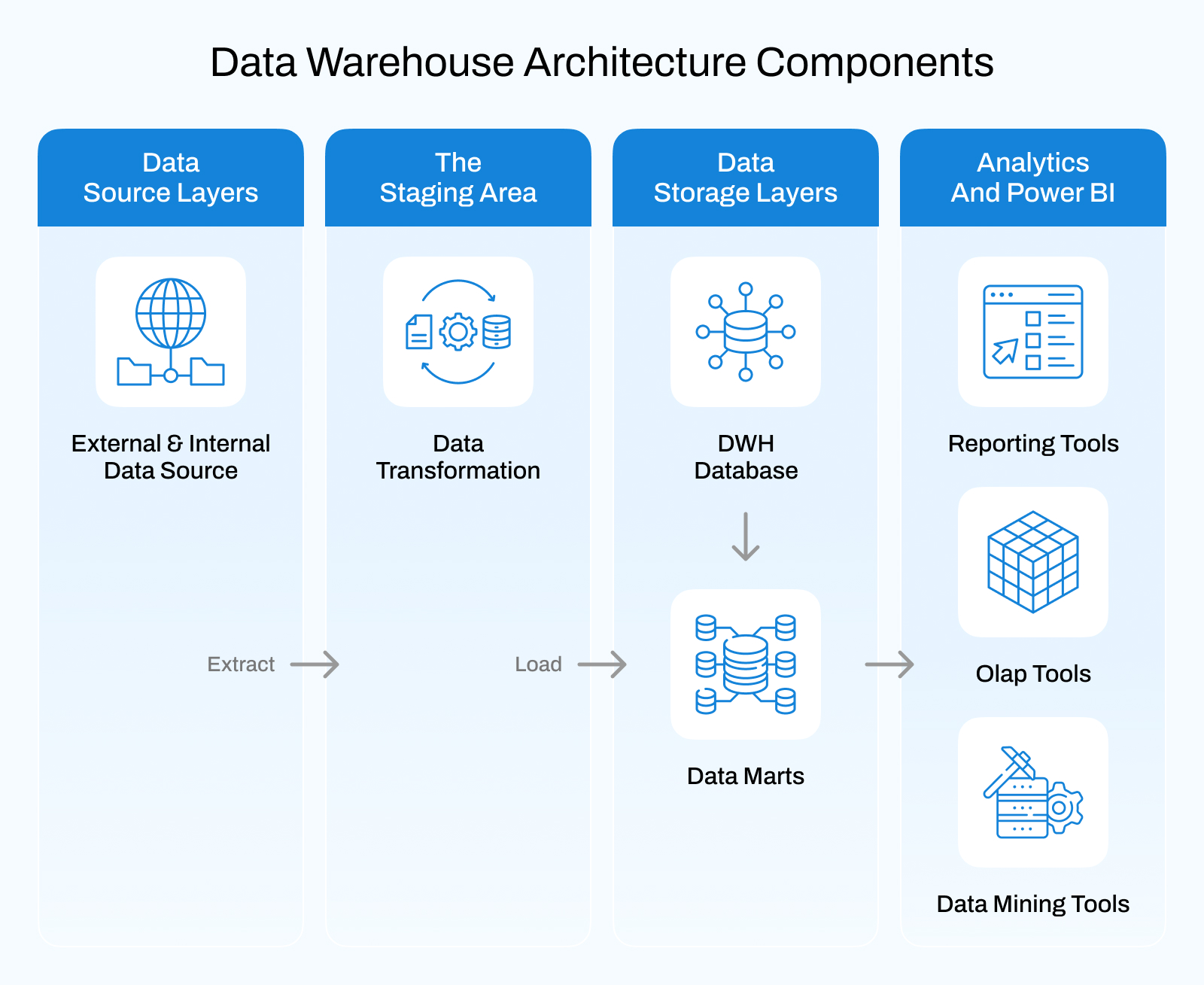
- Data Sources: Here comes your sources of data. It may be sourced through various applications, including CRM systems, ERP software, websites, mobile applications, IoT devices, or third-party tools. Your business also expands, which means that the number and quantity of sources of data increase; thus, your architecture should be scaled to accommodate various and expanding inputs.
- Data Ingestion Layer: This layer handles the transfer of data from source systems to the warehouse. It has ETL and ELT pipelines that retrieve data, load it, and put it in a state where it can be analyzed. A scalable ingestion layer is a system that ensures that any large amount of data or unexpected peaks do not slow down the system.
- Data Storage Layer: Here is where the real information resides. Modern data warehouses put a distance between storage and compute, with the ability to store large volumes of structured and semi-structured data without affecting performance. The storage layer must be economical, safe, and able to support the growth of data over time.
- Data Processing and Compute Layer: This element deals with queries, transformations, and calculations. It is what drives dashboards, reports, and analytics. Scalable architectures enable compute resources to scale on their own, meaning their performance remains constant as additional users and queries are added.
- Metadata and Management Layer: Metadata lets you know what data you possess, the origin of that data, and how this data is utilized. The layer assists in data cataloging, lineage tracking, and governance. It is more critical when the warehouse expands, and more teams use one set of data.
- Access and Analytics Layer: This is the top-most layer of the architecture. Here, BI tools, reporting dashboards, and analytics applications are linked to retrieve insights. An apt access layer would mean that the query responds quickly and the various user roles access it safely. With the right BI services, this layer ensures decision-makers get real-time, role-based insights that support faster and more accurate business decisions.
How to Build a Scalable Data Warehouse: Proven Best Practices
The initial step of the process will help you to create a scaled-up system based on your data, users, and analytics requirements. A proper foundation also makes sure that you do not create performance bottlenecks, manage costs, and more easily adapt to changes in data volumes and workloads over time. Here are some of the proven data warehouse best practices for enterprise analytics you can follow.
Choose the Right Data Warehouse Architecture
Scalability is built on your modern data warehouse architecture. When this foundation is not strong or not properly planned, your system might be effective at first, but it will not be able to keep up with an increase in data volume and users, as well as analytics requirements. Having a poor architectural design would frequently result in repetitive re-work, poor response time, system failure, and escalating operational expenses as time goes by.
Modern data warehouses usually follow one of these data warehouse architectures:
- Centralized Architecture: One data warehouse where all the data is stored. It is easy to manage, yet it may have issues in performance as data and user load grow.
- Distributed Architecture: The information is distributed among two or more nodes, and workloads are distributed and processed in parallel to enhance scalability.
- Lakehouse Architecture: It offers the scalability of a data lake and a traditional data warehouse, which is fine in analytics and large-scale data processing.
A traditional centralized eCommerce company experienced significant delays in seasonal sales because the company used a heavy query load during those periods. Moving to a distributed architecture enabled them to scale compute autonomously and lowered report latency by more than 60% during peak traffic.
According to studies conducted by industries, almost 70% of the issues associated with the performance of data warehouses are attributed to poor architectural choices that are made during the initial stages.
Leverage Cloud-Based Data Warehousing (Cloud-Based vs On-Premise)
On-premise data warehouses usually do not have the ability to scale, since they are based on hard infrastructure, need high initial capital investment, and require continuous maintenance. When comparing cloud-based vs on-premise, with an increase in data, hardware upgrades become costly and time-consuming. Cloud-based data warehousing eliminates these constraints by providing scalability that is flexible and on-demand, including decreased overheads of operation.
Solutions such as Snowflake, Amazon, Google BigQuery, Azure Synapse, and Redshift data warehouse enable businesses to:
- Data grows independently and is stored and processed.
- Pay only for the resources they actually use
- Support the burst of data or user activity without performance problems.
A healthcare analytics company has moved its on-premise warehouse to the cloud. Consequently, they saved 35% on infrastructure and achieved higher query throughput in real-time dashboards for clinician and analyst use.
This shift highlights how a cloud data warehouse enables cost efficiency, scalability, and real-time analytics without infrastructure limitations.
Design for Scalability with the Right Data Modeling Approach
Data modeling is a huge influential factor in the performance of your warehouse as data increases. A model that is not well designed adds complexity to queries, slows down analytics, and becomes more challenging to maintain in the long run. A scalable data model, on the other hand, is faster to query, provides easier reporting, and offers extended flexibility.
Common scalable data modeling approaches include:
- Star Schema: Easy and quick, suitable for BI reporting and dashboards.
- Snowflake Schema: More normalized and storage-efficient, appropriate to complex dimensions.
- Data Vault: It is designed with high scalability, auditability, and frequent data modifications.
A highly normalized schema was used in a logistics company that had a slow dashboard performance. Dashboard loads decreased by almost 50% (previously 45 seconds per load, now less than 8 seconds per load) after switching to a star schema to support analytics workloads.
When it comes to data warehouse best practices for large data volumes, it is necessary that you choose the right data modeling approach according to your business.
Optimize Data Ingestion with ETL / ELT Pipelines
Scalability does not only take place in terms of data location, but it also involves the efficiency with which the data is received and handled. Weak or slow pipelines will soon become bottlenecks as data volume grows.
Currently, scalable systems favor ELT (Extract, Load, Transform) instead of traditional ETL:
- Raw data is initially loaded in the warehouse.
- The transformations are done inside the warehouse with scaling computing power.
One of the fintechs with millions of transactions per day went through with the ETL to ELT pipelines. This transformation cut down the data processing time by half and made it possible to detect and analyze fraud and analytics almost in real-time.
Organizations that go with data pipeline development claim up to 40% increased availability of data in analytics and reporting.
Plan for Performance Optimization in the Data Warehouse from Day One
Most teams consider performance optimization as an issue to be addressed in the future. By the time performance problems are observable, it usually takes a major redesign and increased expenditures. Planning performance as part of enterprise data modernization helps prevent these issues at an early stage as data volumes grow.
Best practices for scalable performance include:
- Scan time reduction by partitioning large tables
- Using clustering and indexing strategically
- Caching frequently used queries
- Constantly monitoring query behavior and workloads monitoring.
An analytics platform used in retail was partitioned by date and area. This saved 30% on query costs and shorter response time during peak business hours.
Among the most frequent reasons that make businesses feel compelled to replace or rebuild data warehouses is performance.
Ensure Data Quality and Governance at Scale
The larger your data warehouse, the harder it is to ensure data quality and data governance. In the absence of proper controls, there is a rise in inconsistency, distrust in the data, and business users cease to use reports and dashboards.
Good governance practices entail:
- Automated data validation and quality checks
- Metadata and data catalog management
- Authorization of sensitive data.
- Track data lineage to know how data was created and changed.
A multinational company launched an automated test of data accuracy on the pipelines and achieved a 65 percent decrease in mistakes in reporting, which restored trust among business teams.
IBM states that, on average $12.9 million per annum, poor quality of data costs organizations.
Conclusion
As we have discussed the data warehouse best practices, one thing is clear: planning prior to making the right choices is what comes to everyone’s mind when we build a scalable data warehouse. It is very important to check how you design your architecture, manage your data pipelines, and look after the performance. These factors decide the future growth of your system.
When you focus on the scalability properly, you start seeing the big difference, like your team gets faster insights, overall cost decreases, and you can rely more on data to make mindful decisions at the right time. Most importantly, even after the data volume increases, the warehouse continues to support your business decisions. After all, playing with data is really challenging as it can bring you a lot of value.
A data warehouse that works well doesn’t just store data, but it keeps your analytics strong and future-ready. It’s the right time to invest in modernizing your data warehouse so that you can make your business ready for the future. Partner with SPEC INDIA for data warehouse development services, as we better know your data challenges, and our team of experts understands scalability, performance, and real business needs.
SPEC INDIA is your trusted partner for AI-driven software solutions, with proven expertise in digital transformation and innovative technology services. We deliver secure, reliable, and high-quality IT solutions to clients worldwide. As an ISO/IEC 27001:2022 certified company, we follow the highest standards for data security and quality. Our team applies proven project management methods, flexible engagement models, and modern infrastructure to deliver outstanding results. With skilled professionals and years of experience, we turn ideas into impactful solutions that drive business growth.
Table of contents
- Key Components of a Scalable Data Warehouse Architecture
- How to Build a Scalable Data Warehouse: Best Practices
- Choose the Right Data Warehouse Architecture
- Leverage Cloud-Based Data Warehousing
- Design for Scalability with the Right Data Modeling Approach
- Optimize Data Ingestion with ETL / ELT Pipelines
- Plan for Performance Optimization in the Data Warehouse from Day One
- Ensure Data Quality and Governance at Scale
- Conclusion
Delivering Digital Outcomes To Accelerate Growth
Let’s TalkTable of contents
- Key Components of a Scalable Data Warehouse Architecture
- How to Build a Scalable Data Warehouse: Best Practices
- Choose the Right Data Warehouse Architecture
- Leverage Cloud-Based Data Warehousing
- Design for Scalability with the Right Data Modeling Approach
- Optimize Data Ingestion with ETL / ELT Pipelines
- Plan for Performance Optimization in the Data Warehouse from Day One
- Ensure Data Quality and Governance at Scale
- Conclusion
Delivering Digital Outcomes To Accelerate Growth
Let’s Talk


Let’s get in touch!
India
SPEC House, Parth Complex, Near Swastik Cross Roads, Navarangpura, Ahmedabad 380009, INDIA.
-
 +91-79-26404031, 32-33-34
+91-79-26404031, 32-33-34 -
 [email protected]
[email protected]
