

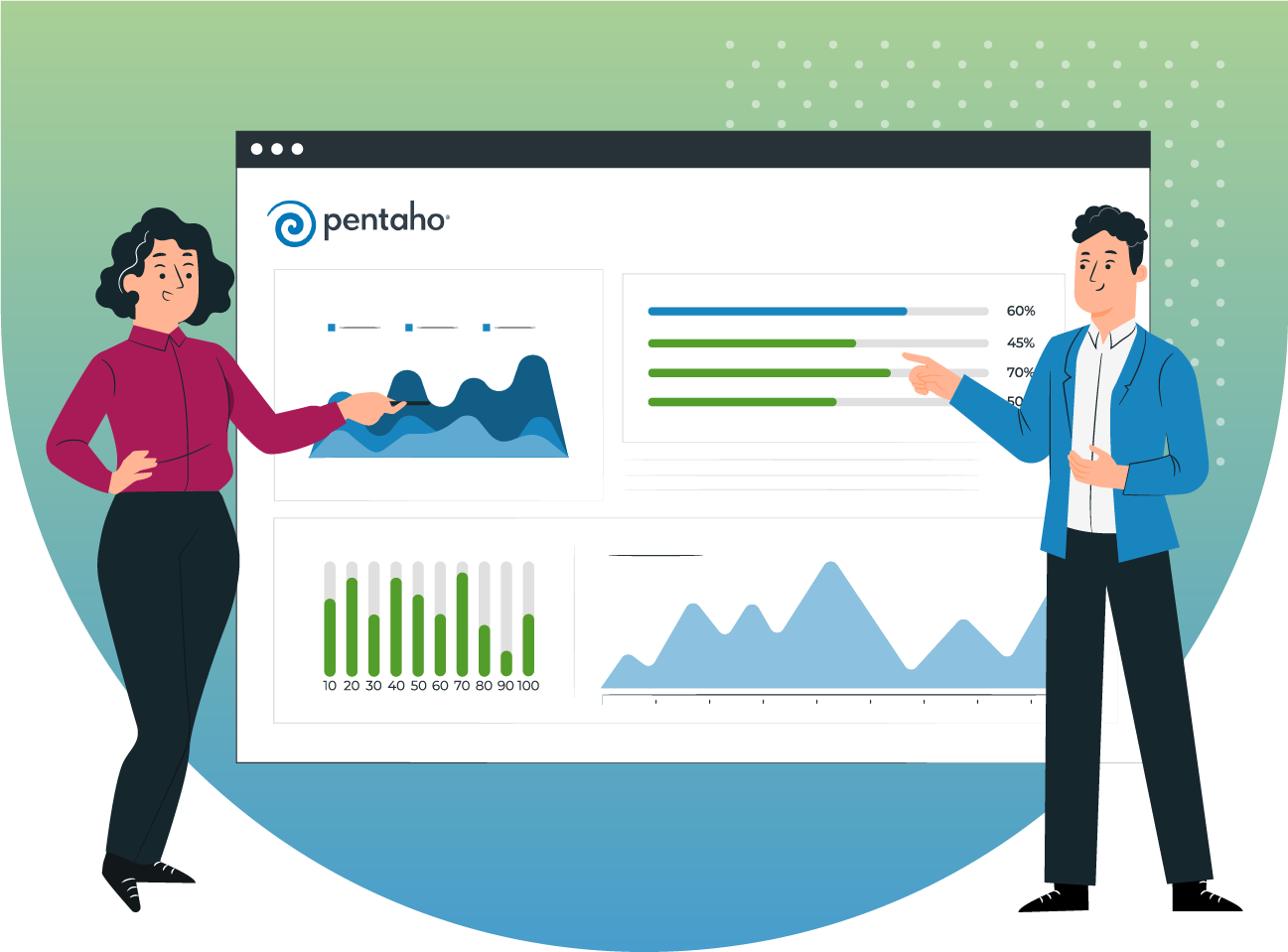
Leverage Pentaho For End-to-End Data Integration And Analytics At Scale. Pentaho is a leading business intelligence platform that offers data integration, analytics, and mining capabilities. It is now a part of Hitachi Vantara and is used by enterprises and startups alike to make more informed decisions. SPEC INDIA’s Pentaho consulting and Pentaho analytics solutions enable organizations to put data to work for better and timely decision-making.















Pentaho is a leading business intelligence platform that offers data integration, analytics, and mining capabilities. It is now a part of Hitachi Vantara and is used by enterprises and startups alike to make more informed decisions. SPEC INDIA’s Pentaho consulting and Pentaho analytics solutions enable organizations to put data to work for better and timely decision-making.
PDI, known as Kettle, is the component of the Pentaho suite and offers ETL (Extract, Transform, and Load) capabilities. Our Pentaho BI experts possess hands-on expertise in ETL processes to collect, clean, and store data using an easy, accessible, and uniform format.

With the powerful Report Designer tool, our team of Pentaho developers generates custom visualizations as per the needs to offer real-time data analytics and predictive analytics.

We present data in easy-to-understand, customized, and interactive dashboards, making it super-easy for organizations to make strategic decisions by accessing important data easily.
We help you make the most of the Pentaho Business Analytics Platform to combine and analyze all types of data, giving more power to users and business teams.

Our Pentaho BI consultants understand your business needs very closely and help you set up Pentaho-based business intelligence solutions covering every aspect.
Our Pentaho BI developers and designers deploy smart algorithms and processes to simplify data collection and utilize various techniques to categorize bulk data.

Our expert team of Pentaho developers and Pentaho designers make the most of the Pentaho suite to access, integrate, correlate, visualize and present the data that can improve and impact decisions.
Our years of experience combined with expertise in business intelligence help businesses meet their unique BI and data analytics needs to stand out from the crowd with data-backed strategies.
Pentaho’s Data Integration capability is world-famous and loved by data enthusiasts across the world. It ensures your data, big or small, structured or unstructured, is appropriately governed and blended based on its timeliness and relevance.
Pentaho uses a metadata-driven approach that allows users to specify what to do exactly and not how to do it. This allows developers to choose from a wide range of predefined plugins and widgets and tell them what to do as per requirements. This makes developers’ jobs easier and offers more flexibility in creating data manipulation jobs.
PDI offers intuitive and drag-and-drop interfaces, making it very easy to learn and use. It saves a lot of time with prebuilt components to rapidly onboard data from various sources. Developers can also add their own custom extensions easily and quickly with a plug-in architecture. It lets developers create data pipelines in minutes by using Spoon (PDI Client) which is a no-code GUI and editor for running jobs and transformations.
Pentaho’s architecture is capable to handle extremely large data sets. PDI is used for enterprise-level data integration, blending, and data cleansing. It is necessary to reduce the overhead of data integration and blending so that data-driven enterprises can focus on analyzing data to drive decisions. Pentaho simplifies the creation of data pipelines and processes data at scale.
Data from any source in any environment – this sums up the capability of PDI in one sentence. PDI is an extremely flexible tool that offers a range of features that include integration, ingest, and preparing of data from any source. It offers broad connectivity to a variety of data sources that include structured, semi-structured, and unstructured data whether they are in the cloud or on-premise.
PDI delivers exceptional performance even when it comes to processing a large amount of data. Using PDI, organizations can gain real insights from data with less complexity and time. It is a Lumada DataOps Suite product that enables organizations to make good use of data, simplifying data management across the organization without any complexity and at speed.
Possesses excellent data integration capabilities, includes migration from the database to the application.
Our Pentaho BI Developers are experts in the latest technologies and the entire Pentaho suite, delivering top-notch solutions for data integration, analytics, and reporting. Let us help you unlock the full potential of your data.
Hire Pentaho Consultants
Discover the diverse range of industries we proudly support with our innovative software solutions to companies of different business verticals. Our expertise spans multiple sectors, ensuring tailored services for every unique need.
Pentaho is an end-to-end business intelligence platform that offers data integration. OLAP services, data mining, ETL processes, and analytics capabilities.
Pentaho ETL Tool, also known as Pentaho Data Integration (PDI) offers powerful Extraction, Transformation, and Loading (ETL) capabilities. It is a leading open-source ETL application, popularly known as Kettle.
Yes, Pentaho is a product of Hitachi Vantara and it is an open-source platform for data integration and analytics capabilities.
Pentaho Kettle is an open-source data integration tool that provides ETL processes. Kettle stands for Kettle Extraction Transformation Transport Load Environment.
Pentaho is open-source and it also provides different editions: a community edition and an enterprise edition. It is now a part of Hitachi Vantara.
Pentaho Spoon is a desktop application (PDI client) that can be installed on your computer and used to run, edit, and debug transformations and jobs.
SPEC House, Parth Complex, Near Swastik Cross Roads, Navarangpura, Ahmedabad 380009, INDIA.

This website uses cookies to ensure you get the best experience on our website. Read Spec India’s Privacy Policy












