

Oracle Database Indexing: Boosting Performance and Efficiency
In the dynamic world of data, time is of the essence, and Oracle Database Indexing takes center stage as your superhero, dedicated to ensuring that your system operates at lightning speed while data retrieval becomes as smooth as spreading butter on warm toast.
One of the key features that contribute to its performance is indexing. In this blog, we will delve into the world of Oracle Database Indexing, exploring what it is, how it works, and why it’s crucial for optimizing query performance.

What is an Oracle Database Index?
It’s a data structure that allows the database management system to quickly locate and retrieve the rows that match a certain query. This allows for efficient data retrieval, especially when dealing with large datasets.
Example: Imagine you have a library with thousands of books, and you want to find a specific book among them. Without an index, you would have to go through each book one by one until you find the one, you’re looking for. An index, in this context, is like the library’s catalog.
Once we run that query, what exactly goes on behind the scenes to find employees who are named Jenny?
The database would literally have to look at every single row in the Employee table to see if the Employee_Name for that row is ‘Jenny’. And, because we want every row with the name ‘Jenny’ inside it, we cannot just stop looking once we find just one row with the name ‘Jenny’, because there could be other rows with the name Jenny.
So, every row up until the last row must be searched – which means thousands of rows in this scenario will have to be examined by the database to find the rows with the name ‘Jenny’. This is what is called a full table scan.
How Does an Index Improve Performance?
Think of it like a phone book. Instead of reading every name in the phone book to find a person’s number, you can use the index (the alphabetical order) to quickly locate the right page where their name is listed. This saves a lot of time.
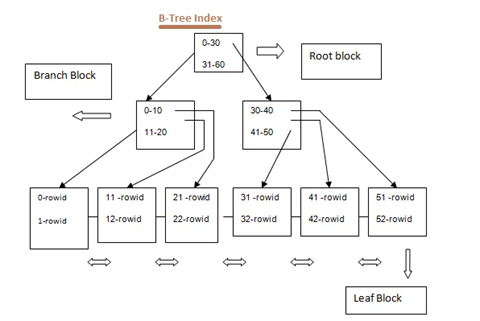
Now, if this index is organized in a particular way, like a B-tree, it not only helps you find things fast but also keeps them neatly sorted. Sorting is like arranging items in order, just like organizing your books on a shelf. When things are sorted, it becomes even easier to find what you need because they are in a logical order.
When we make a B-tree index for the “Employee_Name” column, it’s like making an organized list of employee names. Imagine the names are in alphabetical order, from A to Z.
Now, if we want to find an employee named “Jenny,” we don’t have to search through the whole employee list. Instead, we can use the index, which is like a quick guide. It tells us where all the names that start with “J” are located in the list.
Since the index is sorted, it’s much faster to find names. All the “J” names are right next to each other in the index. Plus, the index keeps track of where each name is in the actual employee table, so we can easily get other info about the employees, like their job titles or salaries.
In a nutshell, the index helps us find names quickly because it’s like a sorted list with pointers to where the names are in the employee table.
What Exactly Is Inside an Oracle Database Index?
So, now you know that a database index is created on a column in a table and that the index stores the values in that specific column. However, it is important to understand that a database index does not store the values in the other columns of the same table.
For Example: If we create an index on the Employee_Name column, this means that the Employee_Age and Employee_Address column values are also not stored in the index. If we did just store all the other columns in the index, then it would be just like creating another copy of the entire table – which would take up way too much space and would be very inefficient.
An index also stores a pointer to the table row So, the question is if the value that we are looking for is found in an index (like ‘Jenny’), how does it find the other values that are in the same row (like the address of Jenny and his age)? Well, it’s quite simple – database indexes also store pointers to the corresponding rows in the table.
We can say that in Oracle row id is working as a pointer for the row.
How Works Pointers to the Corresponding Rows in the Table
- An index is a list of index values and row IDs (ROWIDs)
- ROWIDs are physical pointers to the database tables that give you the fastest access to rows.
- ROWIDs do not change during the life of a row—they only change when you dump and reload a database.
- If you delete a row and create a new identical row, it might have a different ROWID.
- In short, when oracle refers to pointers to the corresponding rows in the table it refers to the rowid of the corresponding rows in the table.
- Oracle locates rows within an index by traversing the index tree. Once a row is located, the ROWID accesses the data.
- Oracle does not lock the whole index tree while it looks for the row, it only locks the block that contains the row. Therefore, other users can simultaneously access rows in the same database.
How Does Oracle Database Indexing Work?
Oracle by default uses a B-tree (Balanced Tree) structure for indexing. B-trees are highly efficient for both insertion and retrieval operations.
Each index entry consists of a key value and a pointer to the corresponding row in the table.
The keys are stored in a sorted order, allowing fast binary search operations.
Types of Indexes in Oracle:
Implicit Index:
Whenever we create a column(s) with Primary key constraints, Oracle implicitly creates a Normal index (Clustered Type Index). This index is not a Unique index. Why because those columns already have uniqueness because of Unique or Primary key constraints (NOT NULL).
Explicit Index:
Explicit Indexes are user-defined. Explicit index created by “Create Index Command”.
- Unique Index: A unique Index is created using the “Create Unique Index” Statement. You should create a unique index only on those columns having unique or primary key constraints. If you have created a unique index on those columns which not have a unique or primary key constraint then also unique index restricts you from inserting duplicating data on those columns.
Syntax: CREATE UNIQUE INDEX index_name ON table_name(column1,column2,...);
Example: CREATE UNIQUE INDEX i_emp_mobile_no ON employee(emp_mobile_no);
- Composite Index: Two or more columns combined to form a composite index with higher selectivity. If all columns selected by a query are in a composite index, then Oracle can return these values from the index without accessing the table. Composite indexes should be avoided as they are large in size and can have a performance overhead. Consider creating a composite index on columns that are frequently used together in WHERE clause conditions combined with AND operators, especially if their combined selectivity is better than the selectivity of either column individually. Consider indexing columns that are used frequently to join tables in SQL statements.
Syntax: CREATE INDEX index_name ON table_name (column1, column2,...);
Example: CREATE INDEX i_emp_name ON employee (first_name, last_name);
- B-tree Index: In general, the BTree index would be placed on columns that were frequently used in the predicate of a query and expect some small fraction of the data from the table to be returned.
- Good for high-cardinality data
- Good for OLTP databases (lots of updating)
- Use a large amount of space
- Easy to update
Syntax: CREATE INDEX index_name ON table_name (field_name);
Example: CREATE INDEX i_emp_name ON employee (employee_name);
- Bitmap Indexes: Bitmap indexes are structures that store pointers to many rows with a single index key entry. In a bitmap index, there will be a very small number of index entries, each of which points to many rows. Bitmap indexes are best used on low cardinality data, this is where the number of distinct items in the set of rows divided by the number of rows is a small number.
- Good for low-cardinality data
- Good for data warehousing applications
- Use relatively little space
- Difficult to update
Interesting Reads: SQL DBA Services for One of the Largest ERP System
- Function-Based Index: A function-based index calculates the result of a function that involves one or more columns and stores that result in the index. The index expression can be an arithmetic expression or an expression that contains a function such as a SQL function, PL/SQL function, and package function.
Note: that a function-based index can be a btree or bitmap index.
Remember, function-based indexes require more effort to maintain than regular indexes, so having concatenated indexes in this manner may increase the incidence of index maintenance compared to a function-based index on a single column.
Syntax: CREATE INDEX index_name ON table_name (expression);
Example: CREATE INDEX i_employee_name ON employee(UPPER(employee_name));
Difference Between B Tree and Bitmap Index:
- Syntax differences: The bitmap index includes the “bitmap” keyword. The btree index does not say “bitmap“.
- Cardinality differences: The bitmap index is generally for columns with lots of duplicate values (low cardinality), while b-tree indexes are best for high cardinality columns.
- Internal structure differences: The internal structures are quite different. A b-tree index has index nodes (based on data block size), it is a tree form.
What is a Clustered and Non-Clustered Index?
Clustered Index:
A clustered index is unique for any given table and we can have only one clustered index on a table. The leaf level of a clustered index is the actual data and the data is reported in the case of the clustered index. Clustered indexes are Physically stored in order (ascending or descending) Only one per table When a primary key is created a clustered index is automatically created as well.
If the table is under heavy data modifications or the primary key is used for searches, a clustered index on the primary key is recommended. Columns with values that will not change at all or very seldom are the best choices. ie. Dictionary.
Non-clustered index:
Up to 249 non-clustered indexes are possible for each table. In the case of a non-clustered index, the leaf level is actually a pointer to the data in rows so we can have as many non-clustered indexes as we can on the db.
Step-by-Step Process of How Oracle Database Indexing Works:
Index Creation:
When you create an index on a table column, Oracle extracts the data from that column and organizes its index.
Query Execution:
When a query is executed that involves the indexed column, Oracle quickly locates the relevant rows.
Data Retrieval:
Once the index points to the rows that match the query conditions, Oracle retrieves the data from the table using the pointers stored in the index.
Why Use Oracle Database Indexes?
- Improved Query Performance: Indexes significantly speed up query execution. Without indexes, the database would need to perform a full table scan, which can be slow and resource-intensive, especially for large tables.
- Reduced I/O Operations: Indexes reduce the number of I/O operations needed to retrieve data. Since indexes store a subset of the data and are smaller in size, reading an index is faster than reading the entire table.
- Optimized Joins: When joining multiple tables, indexes on the join columns can make a significant difference in performance, as they help the database engine find matching rows efficiently.
- Enforced Uniqueness: Indexes can enforce the uniqueness of values in a column, ensuring data integrity.
- Sorting: Indexes can help in sorting query results.
Challenges of Using Indexes
While Oracle Database indexes offer substantial benefits, they are not without their challenges.
- Overhead: Indexes consume disk space and require maintenance, which can impact overall database performance.
- Maintenance Overhead: Indexes need to be updated whenever data in the indexed columns is modified, which can slow down data manipulation operations like inserts, updates, and deletes.
- Choosing the Right Index: It’s essential to select the appropriate columns for indexing. Over-indexing or using the wrong columns can lead to decreased performance.
- Choosing the Right Query: It’s essential to select the appropriate query that uses the right index for indexing.
Interesting Read: Oracle Performance Tuning: Root Cause, Problems, And Solutions
Conclusion:
Indexing is like a super tool for making searches faster and handling big piles of data with ease. Indexes are like shortcuts that make finding information in a database faster and easier when they are used properly.
However, you need to plan and take care of them properly to make sure they keep working well without adding extra work.
To get the most out of Oracle Database in your projects, it’s important to learn how indexing works and make smart choices.
SPEC INDIA is your trusted partner for AI-driven software solutions, with proven expertise in digital transformation and innovative technology services. We deliver secure, reliable, and high-quality IT solutions to clients worldwide. As an ISO/IEC 27001:2022 certified company, we follow the highest standards for data security and quality. Our team applies proven project management methods, flexible engagement models, and modern infrastructure to deliver outstanding results. With skilled professionals and years of experience, we turn ideas into impactful solutions that drive business growth.
Table of contents
Delivering Digital Outcomes To Accelerate Growth
Let’s TalkTable of contents
Delivering Digital Outcomes To Accelerate Growth
Let’s Talk



Let’s get in touch!
India
SPEC House, Parth Complex, Near Swastik Cross Roads, Navarangpura, Ahmedabad 380009, INDIA.
-
 +91-79-26404031, 32-33-34
+91-79-26404031, 32-33-34 -
 [email protected]
[email protected]
